Значна розбіжність між заявленими та незалежно підтвердженими результатами тестування моделі o3 від OpenAI піднімає важливі питання щодо прозорості методологій оцінювання та маркетингових практик у галузі штучного інтелекту.

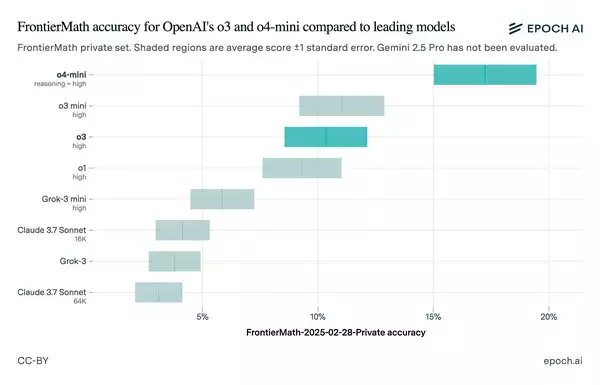
OpenAI публічно представила модель o3 із гучними заявами. Компанія стверджувала про значний прорив у здібностях штучного інтелекту. Маркетингова кампанія фокусувалася на вражаючих результатах тестування. Модель нібито правильно вирішила понад 25% завдань FrontierMath.
Головний науковий співробітник OpenAI Марк Чен підкреслив унікальність досягнення: “Сьогодні всі пропозиції мають менше 2% [на FrontierMath]. Ми бачимо, що з o3 в агресивних налаштуваннях обчислень під час тестування ми можемо отримати більше 25%”. Ця заява прозвучала під час офіційної презентації.
Однак подальші незалежні тестування виявили суттєві розбіжності. Дослідницький інститут Epoch AI, який стоїть за тестом FrontierMath, опублікував інші результати. Їхні тести показали продуктивність близько 10% для публічної версії o3.
Пояснення розбіжностей результатів
Причина значних відмінностей у результатах тестування викликає питання. Epoch AI запропонував декілька можливих пояснень. Методики проведення тестів могли відрізнятися між організаціями.
Інститут висловив своє припущення: “Різниця між нашими результатами і OpenAI може бути пов’язана з тим, що OpenAI оцінює з більш потужним внутрішнім каркасом, використовуючи більше тестового часу [обчислень]”. Також вказувалося на відмінності у версіях тестового набору.
ARC Prize Foundation надала додаткове роз’яснення ситуації. Вони підтвердили, що публічна модель o3 відрізняється від тестованої версії. Фонд зазначив: “Всі випущені обчислювальні рівні o3 менші, ніж версія, яку ми [тестували]”.
Член технічного персоналу OpenAI Венда Чжоу визнав оптимізацію моделі. Він пояснив: “Ми зробили [оптимізацію], щоб зробити [модель] більш економічно ефективною [і] більш корисною в цілому”. Це призвело до компромісу між продуктивністю та практичністю.
Проблеми тестування в індустрії штучного інтелекту
Ситуація з o3 виявляє системні проблеми галузі. Практика бенчмаркінгу в індустрії штучного інтелекту стикається з численними викликами. Компанії часто самостійно публікують результати тестів.
Epoch AI раніше критикували за непрозорість. Інститут не розкрив інформацію про фінансування від OpenAI. Багато вчених не знали про цей зв’язок до публічного оголошення.
Подібні суперечки стають звичним явищем у галузі. Компанія xAI Ілона Маска нещодавно потрапила під критику. Її звинуватили в публікації оманливих порівняльних таблиць для моделі Grok 3.
Meta також визнала використання подвійних стандартів. Компанія рекламувала результати тестування однієї версії моделі. Однак розробникам вона надала доступ до іншої версії. Така практика підриває довіру до заяв технологічних компаній.
Незважаючи на невідповідності, майбутнє моделі o3 залишається перспективним. OpenAI планує випустити потужніший варіант o3-pro. Моделі o3-mini-high і o4-mini вже демонструють кращі результати на FrontierMath.
Ситуація нагадує про необхідність критичного аналізу маркетингових заяв. Результати тестування потребують незалежної перевірки. Прозорість методології має стати стандартом індустрії штучного інтелекту.
#Обіцяли #прорив #ШІ #видали #спрощену #версію
Source link